03 三维圆管泊肃叶流动案例注解
在test_3d_poiseuille_flow_shell案例中,我们将学到
三维模型的建立与模拟
多分辨率粒子分布(不同body采用不同分辨率,但同一body分辨率相同)
自定义光滑长度
流入流出边界
particle_bound_与buffer particle的概念
AlignedBoxByParticle和AlignedBoxByCell的区别自由表面识别
各种density summation的适用场景
更好地施加入口速度条件
这个教程中,我们不区分分辨率(resolution)与粒子间距(particle spacing)的概念,认为两者等价。
body创建
这是壁面与流体的几何的左端局部视图。壁面的粒子间距(ΔLs)是流体的(ΔLf)一半。壁面比流体的边界多延伸出4ΔLf的距离(程序中称为wall_thickness,记为δs),用来放置入口和出口的buffer。

流体网格的左边界为y=0的位置。流体粒子和壁面粒子都被放置在网格的中心。
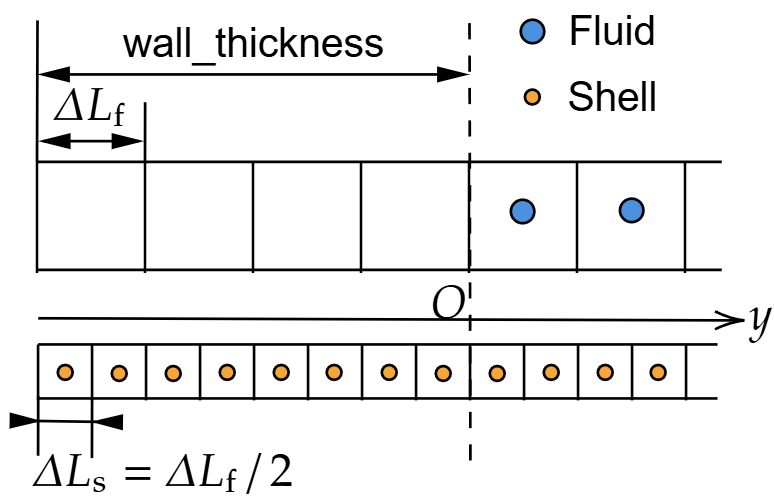
于是我们可以计算出每个壁面粒子(序号为j,从零开始)的y坐标为:
壁面几何与body
圆管壁面是一个单层的柱面,y轴是圆管轴线方向,每个纵截面是一个有65个粒子的环,轴线上一共有116个环,这样总共有7540个壁面粒子。
壁面几何中有两个thickness需要区分。一个是wall_thickness,这是壁面比流体在y方向多延伸出的长度;另一个是shell_thickness,这才是壁面的厚度。
上面的prepareGeometricData()规定了每个壁面粒子的位置、体积、法方向和壁面厚度。x和z坐标由圆的参数方程给出,注意半径比预期的多了ΔLs/2,以避免和流体粒子重叠。y坐标的公式已经在上面给出,只不过程序里将最后一项做了等量代换(其实没必要,还更麻烦了)。对于壳体,粒子的体积是(ΔLs)2,法向量是外法向(流体指向壁面)。
注意shell具有自己的分辨率,是全局分辨率的一半。这就涉及到多分辨率的问题。因为shell的粒子间距是全局的一半,如果shell也采用全局光滑长度进行平滑,势必会过度平滑,造成失真(见下图)。因此,我们有必要相应减小shell的光滑长度,这通过defineAdaptation<SPH::SPHAdaptation>(...)来实现。括号中传入的
第一个参数是光滑长度与粒子间距之比(h/ΔL),默认值是1.3,设为1.15则有h=1.15ΔL;
第二个参数是全局分辨率与本body分辨率之比,默认指是1。这里是按照定义给的:
resolution_ref是全局分辨率,resolution_shell是shell的分辨率。
defineMaterial将材料设置为线弹性材料,似是没有必要(见下图),因为这个案例中壁面是固定不动的。我认为改成Solid也可以。
在下图中,我模拟了几个case。纵坐标是轴向观测点Velocity[15][1]的数据,横坐标是物理时间。original-0、original-1、original-2表示用原始程序跑三次出的结果(每次跑结果都不一样,跑三次可以看出大致趋势);Solid是将线弹性材料改为Solid并不传递任何参数的结果。Solid-NoAdapt在Solid基础上进一步取消了Adaptation。Solid-NoAdapt_Single_resoltion在Solid-NoAdapt的基础上将流体粒子的间距减小为shell粒子的间距,这样就是单一分辨率了。
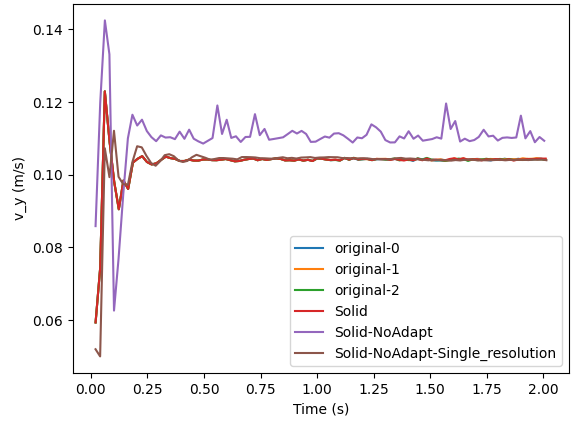
我们可以看到,将线弹性材料改为Solid没有任何影响。多分辨率场景中去掉Adaptation使得结果振荡且偏离原值,但改为单一分辨率后又回复至原值且稳定(看稳态结果)。这说明在多分辨率场景中有必要使用Adaptation修改默认设置。
流体几何与body
使用TriangleMeshShapeCylinder创建了流体的几何。五个参数依次为:轴线方向矢量、流体半径、半长度、网格精度和圆柱中心点坐标。关于SimTK的网格精度,在几何创建中已有介绍,在此不赘。这样一来,流体的几何位于0≤y≤10ΔLf的区间内。
使用inlet_particle_buffer进行了粒子生成。generateParticlesWithReserve<BaseParticles, Lattice>(inlet_particle_buffer)其实与generateParticles<BaseParticles, Lattice>()差不多,区别是将particles_bound_递增了buffer_size(因为用户传入的是0.5,所以递增real particle数目的一半),并且设置inlet_particle_buffer的is_particles_reserved_属性为true。
理解particle_bound_与buffer particle
particles_bound_的概念类似于标准库vector的capacity,而real particle数目类似于标准库vector的size。递增之后,就会多分配一段大小为buffer_size个粒子信息所需的内存。我们称这些额外内存段上的粒子为buffer particle。buffer particle不是真正的particle,它们的粒子属性没有意义,不会参与interaction,更不会写入VTP文件。buffer particle的意义是为inflow的粒子提前分配内存空间(空房间),不然在并行模拟时动态分配内存开销是很大的。
入口流速
入口流速设定为
其中r(x,z)=x2+z2。
从AlignedBox的设定来看,入口速度的盒子长度为10ΔLf,将其平移后,所有−2ΔLf≤y≤8ΔLf区间内的粒子速度被设置为给定的入口流速。
流入边界
定义
流入盒子定义在−R≤x≤R,0≤y≤4ΔLf,−R≤z≤R区间内。它在构造时会从给定的emitter(AlignedBoxByParticle类型)中读取body信息、粒子信息和获取aligned box,然后将给定的inlet_particle_buffer记录为自己的buffer成员,最后确保传入的inflow_particle_buffer的is_particles_reserved_属性为true。
注意这里使用的是emitter是AlignedBoxByParticle,而非入口流速指定那里使用的AlignedBoxByCell。这两个的区别在于AlignedBoxByParticle对象记录的是被构造时AlignedBox区域的粒子ID。所以后续遍历时,无论这些粒子是否跑出了AlignedBox,都会把这些粒子遍历到。而AlignedBoxByCell记录的是cell(CLL中的cell)的ID。后续遍历时,无论粒子初始时是否属于这个cell,只要检测到某个粒子当前在cell里,就会被遍历到。
这里给EmitterInflowInjection传入的必须是AlignedBoxByParticle类型的对象,为什么呢?且看下面流入边界是如何执行的。
执行
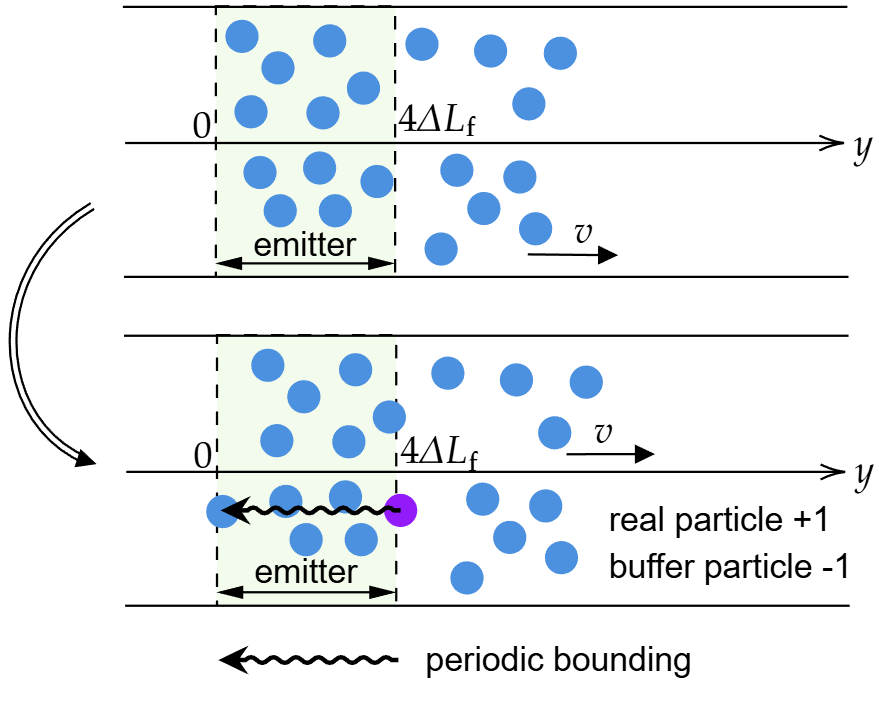
看下面这张图。假设上方是初始粒子分布。注意这里有个容易误解的地方:图上显示的所有粒子,包括emitter区域的粒子,都是real particle。不要误认为emitter区域的是buffer particle。如前所述,buffer particle的属性是没有意义的,只是起到预留内存空间的作用。根据案例设定,emitter右边界在4ΔLf的位置。当时间向前推进,粒子向右移动,程序检测到有一个粒子越出了emitter的右边界,这时,会依次执行:
在这个粒子原位拷贝出一个粒子,使用的是buffer particle的内存。换言之,我们把一个buffer particle转换为了real particle,这一新的particle具有和原粒子一模一样的属性(除了ID)。结果是real particle增加了一个,buffer particle减少了一个。
把旧的particle按周期性边界映射回左边界附近(蛇形箭头),用公式描述就是y′=y−4ΔLf。映射回去的粒子属性设为默认属性。这样我们就保证了emitter永远有足够的粒子来注入内部的bulk flow。
理解了过程,下面来看代码。在内循环结束、更新CLL和邻居表之前执行:
emitter_inflow_injection.exec()会为每一个粒子调用EmitterInflowInjection::update:
首先需获取sortedID,因为属性是按照sortedID存储的。然后用checkUpperBound检查当前粒子是否越出了右边界。如果是,并且buffer尚有足够内存,则原位拷贝一个新的粒子。启用互斥锁的原因是这类边界注入通常可能在并行循环里跑,切换粒子状态、修改粒子数量/容器时必须保证线程安全。
创建完毕后,把旧的粒子映射回左边。其密度设为默认密度,压力按照默认密度计算得出。
流出边界
定义
流出盒子定义在−1.1R≤x≤1.1R,L−4ΔLf≤y≤L,−1.1R≤z≤1.1R区间内。它在构造时会从给定的disposer(AlignedBoxByCell类型)中读取body信息、粒子信息和获取aligned box。
执行
disposer_outflow_deletion.exec()会为每一个粒子调用DisposerOutflowDeletion::update:
在互斥锁保护下,检查当前粒子是否超出了disposer边界,以及当前粒子索引是否小于real particle的数目。如果是,则把这个粒子转为buffer particle。结果是buffer particle数目加一,real particle数目减一。
emitter消耗buffer particle,disposer又提供buffer particle,通过buffer particle和real particle的相互转换,有效地节省了内存空间。
深入探究
容易引起困惑的是
AlignedBoxByCell只遍历box内部的粒子,为什么越界粒子也会被遍历到?为什么这里使用的是while循环,而不是简单的if语句?
按理说update的粒子都是real particle,为什么还要再检查
index_i < particles_->TotalRealParticles(),不是多余吗?
第一个问题容易回答:CLL是在流出边界条件执行完毕后方才执行,所以此时CLL是上一时间步的CLL,这个越界的粒子仍然能够被遍历到。
对于后面两个问题,我们需要深入源码看看。我们首先假设一共有5000个real particle。遍历sortedID为#0-4998粒子(后面提到的ID默认都是sortedID,存储顺序也是按sortedID)时都没有检测到有粒子跑出disposer,遍历到#4999粒子时,检测到#4999越界。另外,因为4999<5000,所以while的条件满足,进入循环。进入particles_->switchToBufferParticle(index_i)看看:
传入的实参index的值是4999。TotalRealParticles()的值是5000,于是last_real_particle_index值是4999。在if判断中,index和last_real_particle_index的值相等,if条件不满足,跳过。最后decrementTotalRealParticles()会将TotalRealParticles()的值减去1。此时#4999粒子已不在real particles的范围内,后续就不会参与interaction和update了。这也是为什么这个函数名叫做switchToBufferParticle。
现在退出BaseParticles::switchToBufferParticle。再次来到while的判断,因为particles_->TotalRealParticles()已经变成4999了,所以while条件不满足,退出循环。
好像while循环和index_i < particles_->TotalRealParticles()判断并没有起作用?这是因为我们选定的越界粒子太特殊了。实际上越界的不一定恰为#4999号粒子。这次我们假设#4000和#4999都越界了,那么在遍历到#4000号时便会使得while条件满足,传入BaseParticles::switchToBufferParticle的index就是4000。last_real_particle_index还是4999。此时4000<4999,if条件满足,进入内部作用域。copyFromAnotherParticle(index, last_real_particle_index)会把#4999粒子的属性拷贝给#4000粒子(安全的,因为#4000粒子即将被剔除real particle,它原本的属性已经无需保留)。然后把#4000粒子和#4999粒子交换。结果是越界粒子变成了#4999,原#4999粒子现在变成了#4000。现在就可以安全地执行decrementTotalRealParticles()了。
退出BaseParticles::switchToBufferParticle。再次来到while的判断。注意此时index_i(#4000)粒子已经具备了原#4999粒子的属性,而原#4999粒子是越界的。如果这里不是while循环而是if判断,那么这个越界的粒子就再也不会被处理了,因为再也不会遍历到#4000了。幸好这里是while。于是再次进入BaseParticles::switchToBufferParticle,交换当前的#4000(原#4999)和当前的#4998,把原#4999粒子也删掉,TotalRealParticles()变成了4998。再次进入while条件判断,原#4998是不越界的,因此while条件不满足。现在我们回答了第二个问题(为什么要while而非if)。
注意,当我们删除粒子时,disposer的loop range并没有更改。因此,尽管real particle的数目已经变成了4998,while循环依旧会遍历到4998和4999。index_i < particles_->TotalRealParticles()的判断,避免了这里把buffer particle也删了(非预期行为)。现在我们回答了第二个问题(为什么要额外判断index_i < particles_->TotalRealParticles())。
补充一下,储存real particles的内存空间是连续的,储存buffer particles的内存空间也是连续的,并且buffer particle紧跟在real particle后面。因此每次删除粒子都是删最后一个real particle,而非直接把越界粒子删掉。这说明了交换粒子的必要性。
定义数值方法
壳体相关
这行是在“定义一个壳体(shell)初始构型修正”的动力学算子,后面通过wall_corrected_configuration.exec()真正执行一次,用来给壳体粒子预计算/写入“构型修正矩阵”B_,主要服务于后续壳体的形变梯度/弯曲形变梯度/应力计算链路。但是这里壁面是固定不动的,所以这个关系的定义和修正其实是多余的。我们也可以认为它是个代码模板,如果后面改成可变性壁面,这里就需要修正了。
如02_SPHinXsys二维槽道流案例注解中介绍的,这两行代码是为了计算曲率,因为壁面是不动的,所以也多余。可以认为是模板。
自由表面识别
这里开启了自由表面识别。尽管这个案例中没有自由表面(溃坝那种),但是在入口边界和出口边界,粒子的邻居是不完整的,只有体相的邻居。而transport velocity correction应该只针对体相进行。所以有必要开启自由表面识别。它会给每个SPH粒子一个indicator,0表示体相,1表示自由表面。在那为什么二维溃坝和二维槽道流没有开自由表面识别呢?
溃坝中没有用到transport velocity correction。而可能用到自由表面识别的density summation是
BaseDensitySummationComplex<Inner<FreeSurface>, Contact<>>类型,但其中BaseDensitySummationComplex<Inner<FreeSurface>>无需indicator判断自由表面,而是强制令密度至少为初始密度(SMAX(this->rho_sum_[index_i], this->rho0_))。因此,density summation也不需要自由表面识别。二维槽道流用到了transport velocity correction。此案例中采用了周期性边界条件,所以边界粒子的邻居并不会因为处在边界而减少。
密度求和
另外,我们看到本例中density summation使用的是DensitySummationFreeStreamComplex类型。它是一种比DensitySummationComplexFreeSurface更软的类型,并且需要用到indicator,而本例恰好也用SpatialTemporalFreeSurfaceIndicationComplex计算了indicator。基于目前学习的三个案例来看(溃坝、槽道流、本例),做density summation的经验规则如下:
自由液面采用
DensitySummationFreeStreamComplex(溃坝)流入流出边界和自由流采用
DensitySummationFreeStreamComplex(本例)没有自由液面,也没有流入流出边界(周期性边界的流入流出不算),采用
DensitySummationComplex(槽道流)
入口速度条件的施加顺序
在槽道流案例中,速度入口在pressure relaxation和density relaxation中间施加:
当时我对此的解释是:
动量方程会更新一步速度,然后才能施加入口速度的条件,这样确保了入口速度是我们所指定的。而连续性方程求解中需要用到速度,因此有必要把入口速度施加放在连续性方程更新之前,确保了使用正确的入口速度来求解连续性方程。
可是在本例中,速度入口是在内循环最后施加的:
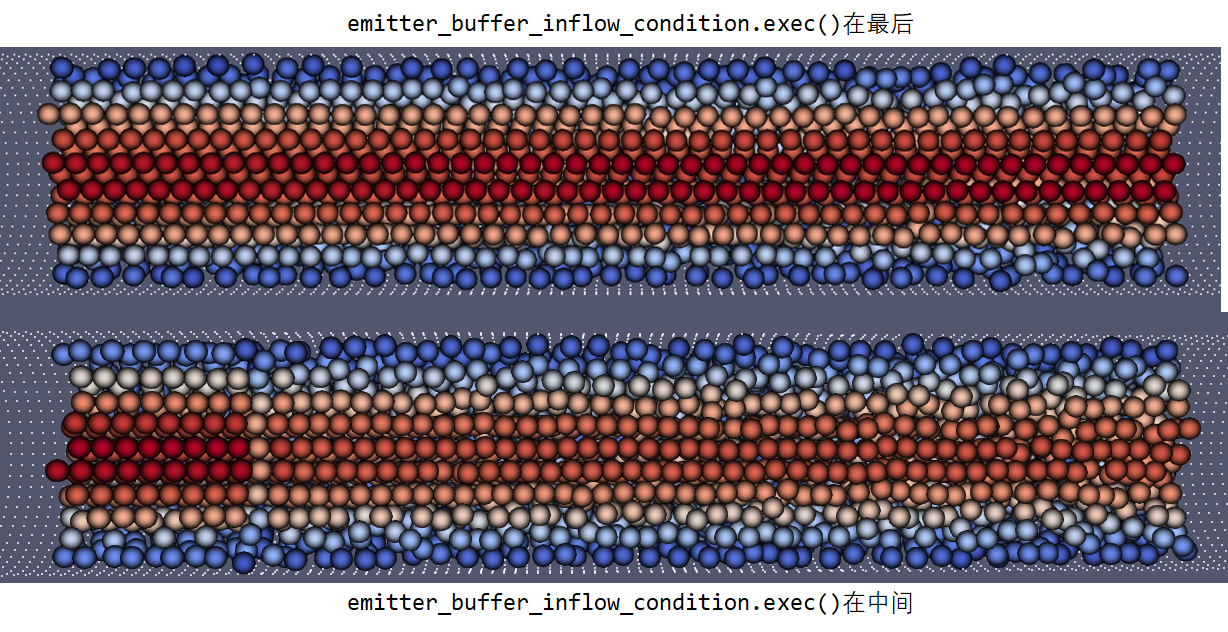
到底哪个对呢?我做了两次试验。第一次,我把本例的emitter_buffer_inflow_condition.exec();调到两次relaxation中间,结果发现甚至没有通过gtest测试:
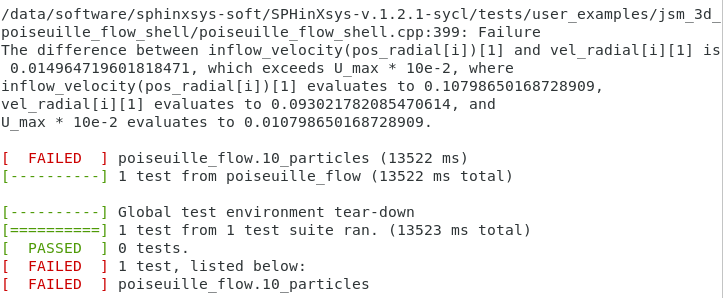
对比一下可视化的结果(颜色表示轴向速度)。当我们把emitter_buffer_inflow_condition.exec();调到中间的位置,内部流体的速度与入口出现了较大差异,而且粒子分布变得更乱了。
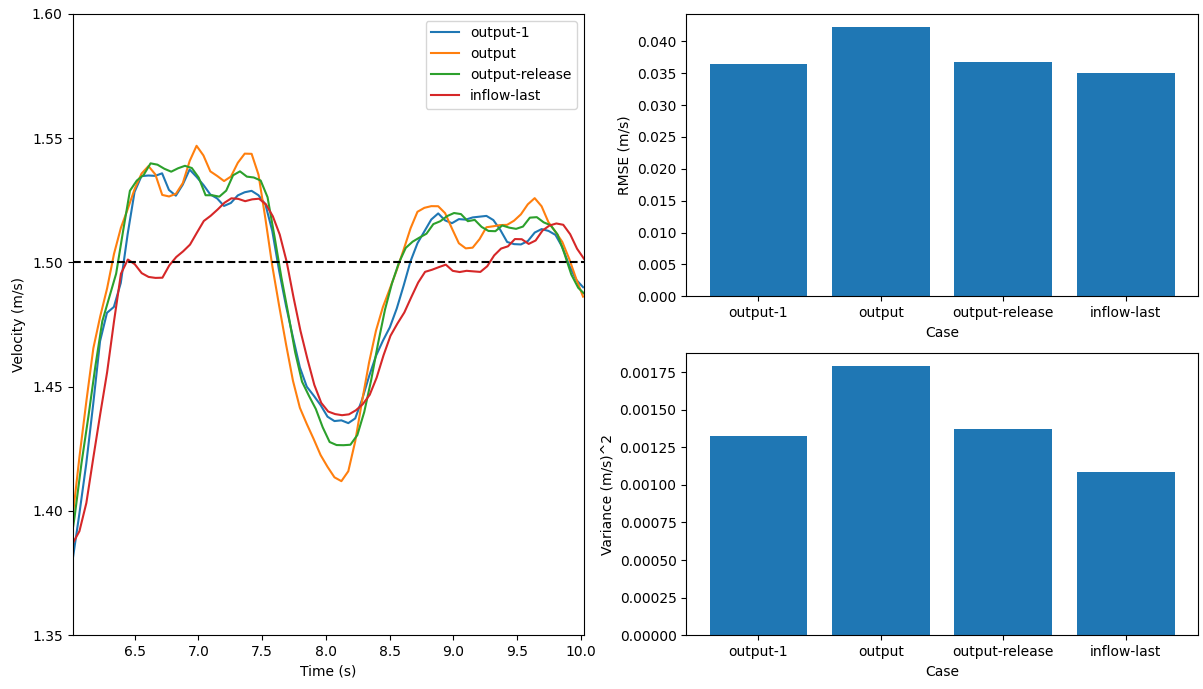
第二次试验,我把槽道流案例的parabolic_inflow.exec();调到了内循环的最后。下图中,名字中有output的案例都是原始代码跑出的结果(微小差异,看平均值)。inflow-last是把parabolic_inflow.exec();调到内循环最后的结果。左图是是轴线上某一点的速度对比,$u_y=1.5$的水平线表示预期收敛到的速度。不难发现,把入口速度条件调到最后,好像更接近目标速度了,而且波动也更小了。右上图中把案例的结果速度与目标速度进行了对比,inflow-last的RMSE最小;右下图计算了每个案例的速度方差,inflow-last的方差也是最小。
从这两个案例可以看出,似乎把入口速度放在内循环最后施加总是更合适的。为什么呢?我不太明白,问了一下AI,下面是它给出的回答。
下面给出一个更自洽、且能解释两次试验现象的理解(结合SPHinXsys现有实现)。结论先行:
对于本例这种开边界 + 注入/删除(
EmitterInflowInjection/DisposerOutflowDeletion)的情形,把入口速度条件放在声学子步(acoustic sub-step)的最后,通常更稳定、整体误差更小。对于槽道流这种周期边界/无注入的情形,把入口速度放在中间或最后都可能工作;但“放最后”往往更像一个稳定的“投影/约束”步骤,你的试验也印证了这一点。
为什么“放中间”反而更差?
关键点是:在SPHinXsys的Verlet分裂时间推进里,pressure_relaxation 和 density_relaxation 并不是“动量方程 / 连续性方程”的严格分割;更准确地说,它们是一个声学时间步(acoustic step)内的两段更新,其中两段都会以速度参与位置推进。
以流体积分的实现为例(在SPHinXsys源码中,Integration2ndHalf::initialization()会执行 pos += vel * dt * 0.5),这意味着:
如果你把入口速度条件放在
pressure_relaxation与density_relaxation之间,那么density_relaxation的初始化阶段会用“已经被你强制到目标剖面后的速度”去推进入口缓冲区粒子的位置半步。这在入口缓冲区相当于对粒子做了一次“强制对流”,它未必与该子步的压力/密度更新相一致,容易造成入口附近粒子出现非物理的聚集/稀疏,从而破坏粒子均匀性;在开边界场景里,这种不均匀还会与注入/删除机制耦合放大。
于是就解释了你看到的现象:
3D Poiseuille:把
emitter_buffer_inflow_condition.exec()挪到中间,会让入口区域粒子分布更乱、内区速度偏离更大,甚至导致gtest不通过。2D channel:把
parabolic_inflow.exec()挪到最后,入口速度与整体场更“平滑地衔接”,波动更小,部分区域更接近target。
为什么“放最后”更稳定、也可能更准?
需要换一个角度看待 InflowVelocityCondition:它更像是一个速度投影/速度松弛(relaxation)算子,而不是“方程求解器的一部分”。它会对盒子内粒子直接改写速度(可带松弛率),但并不会同步修正压力/密度/力等状态。
因此更稳妥的做法是:
先让该声学子步的数值更新(两次relaxation)按照既定分裂格式完成——这包含了该子步内必要的位移推进与压力/密度相关量更新;
在子步末尾再对入口缓冲区的速度做一次投影,使其作为“下一子步开始时”的边界状态。
从算子分裂(operator splitting)的视角看,这相当于在每个声学子步末尾施加一次Dirichlet速度约束:它不强行改变“本子步内部的推进轨迹”,但会保证下一步的边界初值更接近目标剖面,通常带来更好的稳定性。
实用建议:不同边界类型如何放置入口速度条件?
结合本教程两个算例的经验,可以给出一个简单的经验规则:
开边界(有注入/删除、邻域不完整):优先把入口速度条件放在声学子步最后(
pressure_relaxation+density_relaxation之后)。必要时,额外在注入/删除之后(更新cell linked list之前)再补一次入口速度投影,用于让刚被周期映射回入口附近的粒子更快贴合目标剖面。周期边界或无注入:两种顺序都可能可用;若你关心稳定性与整体误差,优先尝试“子步最后投影”。
最后,回到我在槽道流注解里给的那段解释:“连续性方程要用速度,所以必须把入口速度放在密度更新之前”。在SPHinXsys当前实现里,这句话过于理想化了:density_relaxation 不只是“连续性更新”,它还包含位置推进并与压力相关项耦合;因此把入口速度硬插到中间不一定更“物理一致”,反而可能更不一致。
Last updated